

A rendering of the Large Synoptic Survey Telescope’s dome. (Credit: LSST Collaboration)
A new telescope will take a sequence of hi-res snapshots with the world’s largest digital camera, covering the entire visible night sky every few days – and repeating the process for an entire decade. That presents a big data challenge: What’s the best way to rapidly and automatically identify and categorize all of the stars, galaxies, and other objects captured in these images?
To help solve this problem, the scientific collaboration that is working on this Large Synoptic Survey Telescope project launched a competition among data scientists to train computers on how to best perform this task. The Photometric LSST Astronomical Time-Series Classification Challenge (PLAsTiCC), hosted on the Kaggle.com platform, provided a simulated data set for 3 million objects and tasked participants with identifying which of 15 classifications was the best fit for each object.
Kyle Boone, a UC Berkeley graduate student who has been working on computer algorithms in support of the Nearby Supernova Factory experiment and Supernova Cosmology Project efforts at the Department of Energy’s Lawrence Berkeley National Laboratory (Berkeley Lab), devoted some of his spare time to the international machine-learning challenge in late 2018 while also working toward his Ph.D.
“As I worked on job applications I started playing around with this competition to teach myself more about machine learning.” Boone said. Participants could submit their codes up to five times per day to check their performance on a leaderboard for 1 million objects in the test set. The competition ran from Sept. 28, 2018, to Dec. 17, 2018, and Boone was up against 1,383 other competitors on 1,093 teams.
“During the last few weeks I worked really hard on it,” he said, devoting all of his evenings and weekends to intense coding.
“My results started to become competitive, and I rushed to implement all of the different ideas that I was coming up with. It was fun, and several teams were neck and neck until the end. I learned a lot about how to tune machine-learning algorithms. There are a lot of little ‘knobs’ you can tweak to get that extra 1 percent performance.”

Kyle Boone
While giving a science talk on the final day of the competition, he received a text from his fiancée. “She messaged me and said, ‘Congratulations.’ That was pretty exciting,” Boone said. He won $12,000 for his first-place finish, and also participated in a second phase of the competition that was more open-ended and is driving toward more applicable solutions in categorizing the objects that LSST will see – the latest round concluded Jan. 15.
Renée Hložek, as assistant professor of astrophysics at the University of Toronto in Canada who led the Kaggle challenge, said, “It is really refreshing to see how combinations of approaches lead to really innovative and novel solutions.
She added, “We have big plans for the next iterations of PLAsTiCC, since there are many ways in which the real LSST data will be even more challenging than our current simulations.”
She noted that PLAsTiCC was created through a collaboration between two science groups working on LSST: the Transient and Variable Stars Collaboration (TVS) and the Dark Energy Science Collaboration (DESC).
Gautham Narayan, a Lasker Data Science Fellow at the Space Telescope Science Institute who is a member of TVS and DESC and served as a host for the LSST Kaggle competition, noted that the solutions submitted by PLAsTiCC competitors all had different strengths and weaknesses.
“We’re looking at their submissions to see if we can do even better,” he said. It may be possible to mix and match the different solutions to develop an improved code, he said. “We’re really delighted with how it went.”
He added, “Machine learning is advancing so fast. The numbers are staggering to behold.”
Boone said, “The competition really motivated people to think outside the box and come up with new ideas. There were a lot of very interesting ideas that I don’t think have ever been tried before. I think that combining all of the best models is going to give a huge boost and be very useful for LSST.”
In his work at Berkeley Lab, Boone analyzes data taken from telescopes to understand all of the properties of Type Ia supernovae, and develops new models that can provide accurate distance measurements even for distant supernovae. Type Ia supernovae are used as so-called “standard candles” for measuring distances in the universe based on their luminosity, but these measurements can be affected by the size of the galaxy they reside in.

A truck delivers the 128-ton coating chamber for the LSST to the summit of Cerro Pachón in Chile, safely completing a 15-week journey from Deggendorf, Germany. (Credit: LSST Project/NSF/AURA)
Boone said he hopes to apply his programming work for the LSST competition to his work at Berkeley Lab. “It’s very relevant to my own research,” he said, adding that he plans to prepare a scientific paper based on the machine-learning code he wrote for the competition.
Berkeley Lab astrophysicist, UC Berkeley professor, and Nobel laureate Saul Perlmutter, who is Boone’s Ph.D. adviser, said, “Kyle has a been a true leader in our group in applying all of the advances that data science offers to our fundamental science research. This is one of those moments in the progress of science when we get another explosion of new tools – and, ideally, new and surprising science results.”
In Boone’s approach to the LSST Kaggle competition, he started out by developing a code that was specialized for identifying supernovae. And he applied a popular statistical technique called Gaussian processes.
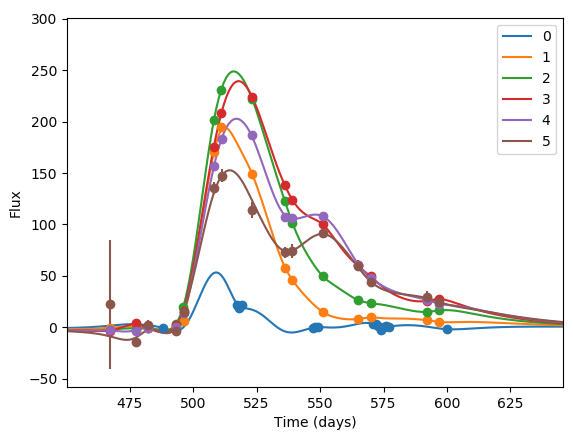
This graph shows a sample of the output from Kyle Boone’s winning code. The graph, produced using a method known as Gaussian processes, shows object light curves over time, sampled at different optical bands. (Credit: Kyle Boone)
“Gaussian processes are basically a way to turn a whole bunch of noisy data points, taken at random points in time, into a smooth curve,” he explained, so the data points are represented by curved graphs that provide clues about the object types.
Real data, unlike the test data set used for the competition, can be messier, Boone noted, as it can be affected by noise from a variety of sources. “Machine-learning algorithms oftentimes don’t take noise into account. That’s a big challenge,” he said.
New experiments such as LSST, which will regularly generate streams of data measured in terabytes and petabytes, will likely lean heavily on machine-learning algorithms just because researchers can’t possibly keep up with the incredible volume of information.
“You can’t have people at every step of the process and we need to automate everything that we can,” he said.
Hložek said she looks forward to sharing the results from the Kaggle competition more broadly with the scientific community, “and to keep testing them on the data going forward.”
PLAsTiCC is supported by a Large Synoptic Survey Telescope Corporation Grant Award and administered by the University of Toronto. The LSST project is supported by the Department of Energy’s Office of High Energy Physics, the National Science Foundation, and private funding raised by the LSST Corporation. The NSF-funded LSST Project Office for construction was established as an operating center under management of the Association of Universities for Research in Astronomy. The competition prizes were paid for by Kaggle Inc.
###
Lawrence Berkeley National Laboratory addresses the world’s most urgent scientific challenges by advancing sustainable energy, protecting human health, creating new materials, and revealing the origin and fate of the universe. Founded in 1931, Berkeley Lab’s scientific expertise has been recognized with 13 Nobel Prizes. The University of California manages Berkeley Lab for the U.S. Department of Energy’s Office of Science. For more, visit www.lbl.gov.
DOE’s Office of Science is the single largest supporter of basic research in the physical sciences in the United States, and is working to address some of the most pressing challenges of our time. For more information, please visit science.energy.gov.