Tag: machine learning
With Little Training, Machine-Learning Algorithms Can Uncover Hidden Scientific Knowledge

Berkeley Lab Researchers Use Machine Learning to Search Science Data
Digging Deep: Harnessing the Power of Soil Microbes for More Sustainable Farming

Teaching Computers to Guide Science: New Machine Learning Method Sees the Forests and the Trees

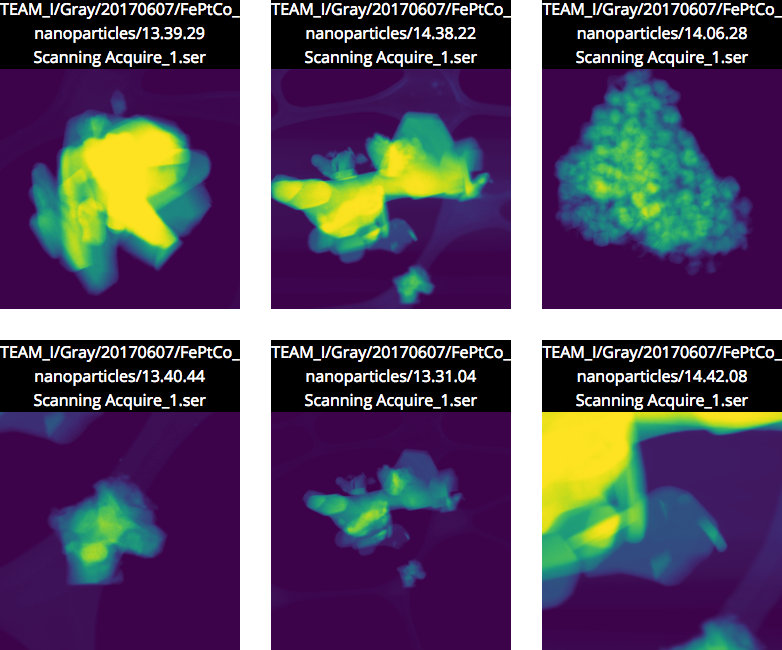
Berkeley Lab ‘Minimalist Machine Learning’ Algorithms Analyze Images From Very Little Data
Applying Machine Learning to the Universe’s Mysteries

New Machine Learning Technique Provides Translational Results