
Adapted from a news release by Robert Sanders
When scientists announced the complete sequence of the human genome in 2003, they were fudging a bit.
In fact, nearly 20 years later, about 8% of the genome has never been fully sequenced, largely because it consists of highly repetitive chunks of DNA that are hard to align with the rest.
But a three-year-old consortium has finally filled in that remaining DNA, providing the first complete, gapless genome sequence for scientists and physicians to refer to.
The newly completed genome, dubbed T2T-CHM13, represents a major upgrade from the current reference genome, called GRCh38, which is used by doctors when searching for mutations linked to disease, as well as by scientists looking at the evolution of human genetic variation.
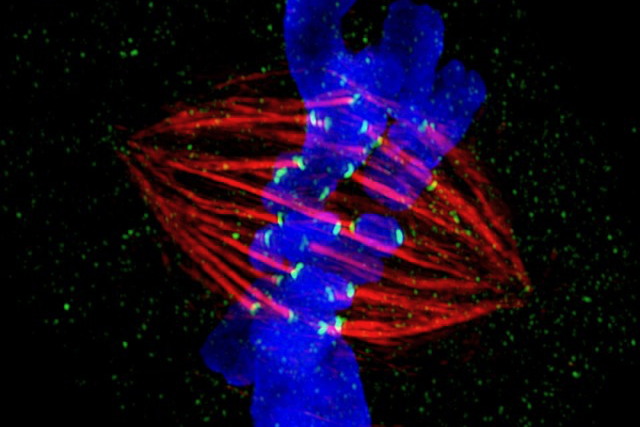
Among other things, the new DNA sequences reveal never-before-seen detail about the region around the centromere, which is where chromosomes are grabbed and pulled apart when cells divide, ensuring that each “daughter” cell inherits the correct number of chromosomes. Variability within this region may also provide new evidence of how our human ancestors evolved in Africa.
“Highly repeated, tightly packed DNA regions of the chromosomes play critical roles in genome organization and function, as well as chromosome segregation,” said Gary Karpen, a senior scientist in Berkeley Lab’s Biosciences Area. “Thus, a deeper understanding of the precise DNA sequences will help reveal components and mechanisms responsible for both health and disease, including cancer and birth defects.”
Karpen, who is also a Professor of Molecular & Cell Biology at UC Berkeley, is an author on a study describing the centromere sequence map generated by the Telomere-to-Telomere Consortium’s T2T-CHM13 project. The paper was published in the journal Science alongside four other studies describing new insights from this newly completed genome.
T2T-CHM13 is a gapless account of all 22 autosomes and the X sex chromosome, composed of 3.055 billion base pairs, the units from which chromosomes and our genes are built. The sequences in and around the centromere total about 6.2% of the entire genome, or nearly 190 million base pairs. After the sequencing was completed, the study team used new techniques to find the place within the centromere where a big protein complex called the kinetochore solidly grips the chromosome so that other machines inside the nucleus can pull chromosome pairs apart.
They found layers of new sequences overlaying layers of older sequences, each composed of repetitive lengths of DNA based on a unit about 171 base pairs long. These 171 base pair units form even larger repeat structures that are duplicated many times in tandem, building up a large region of repetitive sequences around the centromere for the kinetochore to bind.
“DNA is a set of instructions with no one to read it if it doesn’t have proteins around to organize it, regulate it, repair it when it’s damaged and replicate it,” said Nicolas Altemose, first author on the centromere study and postdoctoral fellow at UC Berkeley. “Protein-DNA interactions are really where all the action is happening for genome regulation, and being able to map where certain proteins bind to the genome is really important for understanding their function.”